Difference between revisions of "MATLAB Distributing Computing Server"
m |
|||
| (205 intermediate revisions by 3 users not shown) | |||
| Line 1: | Line 1: | ||
<div style="background-color: #ddf5eb; border-style: solid; width: 80%;"> | |||
NOTE: This page explains the configuration and use of Matlab R2011b and earlier. For R2014b, refer to [[Configuration MDCS]] and [[MDCS Basic Example]]. If you are starting to use Matlab it is recommended to use the latest version available on the cluster. | |||
</div><br><br> | |||
== Benefits of MDCS == | == Benefits of MDCS == | ||
With MDCS, you can submit both serial as well as parallel jobs to one of the central HPC clusters from within your local MATLAB session. There is no need to deal with SGE, or even to log-on to the HPC systems. The internal structure of the clusters is hidden to the end user, they merely act like "black boxes" connected to your local machine and providing you with powerful computational resources. On the other hand, jobs submitted via MDCS are fully integrated into SGE, and have the same rights and privileges like any other SGE batch job. Thus there is no conflict between MATLAB jobs submitted via MDCS and standard SGE batch jobs. | |||
Using MDCS for MATLAB computations on the central HPC facilities has a number of advantages, e.g.: | |||
* Simplified workflow for those who exclusively do their numerics with MATLAB: they can do development, production of results, and post-processing within a unified environment (the MATLAB desktop). | |||
* A "worker" (= MATLAB session without a user interface) does '''not''' check out any "regular" MATLAB license or, what is even more, any Toolbox license even if functions or utilities of the Toolbox are used by the worker; all Toolboxes to which the client which the job was submitted from has access to (regardless whether they are actually checked out by the client or not) can be used by the workers.Considering that the University has only 200 MATLAB licenses, but there are '''224 MDCS worker licenses''', it immediately becomes clear that the '''total number of MATLAB licenses for all users in the University is effectively more than doubled'''! The effect is even more pronounced for the Toolboxes: e.g., there are only 50 licenses for the Statistics Toolbox, but with MDCS an additional "effective" 224 licenses for this Toolbox become available (analogous for all other toolboxes).<br>To allow for a fair sharing of resources, the number of worker licenses a single user can check out at a given instance has been limited to 36. This should be compared to the situation before the introduction of MDCS: how often could one user get access to 36, say, Statistics Toolbox or Signal Processing Toolbox licenses at a time? At peak times, all such licenses are usually checked out.) | |||
* The Parallel Computing Toolbox on your local machine only allows you to use a maximum of 12 workers simultaneously. With MDCS, you can define parallel jobs using more than 12 workers and running across different hosts (compute nodes). Moreover, the Parallel Computing Toolbox provides utilities which simplify the parallelization of MATLAB code. E.g., for "embarrassingly parallel" (aka '''task-parallel''') problems, which are quite common in practice (parameter sweeps, data analyses where the same operations are performed on a set of data, etc.), the <tt>parfor</tt> loop and other tools allow for an easy and rather efficient parallelization. Similarly, for communicating (aka '''data-parallel''') jobs, which are the MATLAB analogue of MPI jobs (implementing the "single program, multiple data" paradigm), tools for "automated" parallelization are available, too, in particular for Linear Algebra operations (distributed and co-distributed arrays). In conjunction with MDCS and the possibility to use the powerful cluster resources, this can lead to a significant speed-up of your MATLAB computations. | |||
Therefore, '''all MATLAB computations on the clusters should by default be done via MDCS'''. Of course, it is still possible to submit MATLAB Jobs as regular SGE jobs (by writing the command that starts MATLAB in non-interactive mode into the submission script and supplying the necessary input arguments and files), but this strategy is deprecated. It leads, due to the limited number of available MATLAB and Toolbox licenses, to a strong competition between HPC users and other MATLAB users across the University. Moreover, cluster jobs often fail immediately after they have started to run since there are no free licenses available (a reliable, full license integration with SGE is non-trivial to implement). With MDCS, this "license availability problem" does not exist since SGE keeps track of the total number of workers currently used, and if the required resources are not available, the job just stays in the queue like any other batch job. | |||
To use any of the functionalities of MDCS, you need to have the '''Parallel Computing Toolbox''' (PCT) installed on your local system. | |||
== Prerequisites == | == Prerequisites == | ||
Before you can use MDCS and submit jobs to the cluster from within a local MATLAB session, a few preparations are necessary, both on the system-wide (host) levek and on a per-user basis: | |||
# On your local machine (PC, workstation, notebook, ...), you must have one of the following MATLAB releases installed:<br><tt>- </tt>R2010b<br><tt>- </tt>R2011a<br><tt>- </tt>R2011b<br>If you want to use Matlab R2014b or later, please refer to these instructions for the [[Configuration MDCS|configuration of MDCS]]. It is important that your local installation includes all toolboxes, in particular the Parallel Computing Toolbox (PCT). It is recommended to install MATLAB from the media provided by the IT Services on their website and follow the instructions there. In that case, all required components (including the PCT) are automatically installed. | |||
# Your local machine must be able to connect to the login nodes of the clusters (<tt>flow.hpc.uni-oldenburg.de</tt> or <tt>hero.hpc.uni-oldenburg.de</tt>) via ssh. | |||
# The system administrator responsible for your local machine must install a couple of files into the directory<br><tt>''matlabroot''/toolbox/local<br></tt> on a Unix/Linux system, or the analogous location for Windows clients. These are the SGE integration files provided by MDCS, which have been customized for our clusters. The names of the files are:<br><tt>createSubmitScript.m</tt><br><tt>destroyJobFcn.m</tt><br><tt>distributedJobWrapper.sh</tt><br><tt>distributedSubmitFcn.m</tt><br><tt>extractJobId.m</tt><br><tt>getJobStateFcn.m</tt><br><tt>getRemoteConnection.m</tt><br><tt>getSubmitString.m</tt><br><tt>parallelJobWrapper.sh</tt><br><tt>parallelSubmitFcn.m</tt><br><tt>startup.m</tt><br>The required [http://www.hpc.uni-oldenburg.de/MDCS/mdcs_sge-integration-files.zip SGE integration files] can be downloaded as a single zipped archive. After downloading, you (or your system adminstrator) can unpack the archive and copy the files to the directory mentioned above. | |||
# The only file from the previous step that needs modification is <tt>startup.m</tt>. There, the fully-qualified hostname of your local machine must be substituted. Thus, the only line in the file<br><tt>pctconfig('hostname','myhost.uni-oldenburg.de');</tt><br>could be changed, e.g., into<br><tt>pctconfig('hostname','celeborn.physik.uni-oldenburg.de');</tt><br>Note, that you adminstrator rights for this step, too (Windows: open editor as admin, Linux: use sudo). | |||
# The following steps must be completed by each user. Start a new MATLAB session and bring up the Parallel Configurations Manager by selecting ''Parallel'' -> ''Manage Configurations''. Create a new "Generic Scheduler" Configuration (''File'' -> ''New'' -> ''Generic''):<br><br>[[Image:GenericSchedulerConfig.jpg|671px|600px]]<br><br>The following fields and boxes must be modified in the register card "Scheduler"<br> | |||
::: ''Configuration Name'': MATLAB name of the configuration (e.g., HERO or FLOW, but could be any name) | |||
::: ''Root folder of MATLAB installation for workers'': E.g., <tt>/cm/shared/apps/matlab/r2011b</tt> if you have R2011b installed on your local machine (otherwise, replace "r2011b" by the appropriate release string; please note the lower cases) | |||
::: ''Number of workers available to scheduler'': Set this to 36 (the maximum number of workers per user) | |||
::: ''Folder where job data is stored'': A directory on your local machine, typically inside your homedirectory, where you have read and write access as, e.g., <tt>/home/myaccount/MATLAB/R2011b/jobData</tt> (note that this directory must already exist, it will not be created automatically!) | |||
::: ''Function called when submitting parallel jobs'': Here you must specify a cell array containing a function handle, the submit host on the cluster, and the location on the remote system where job data are stored (analogous to the "local" job data directory). If you are a user of HERO, the entry could look as follows: <br><tt>{@parallelSubmitFcn,</tt><tt>'hero.hpc.uni-oldenburg.de',</tt><tt>'/user/hrz/abcd1234/MATLAB/R2011b/jobData'}</tt> (note that this directory must already exist, it will not be created automatically!) | |||
::: ''Function called when submitting distributed jobs'': Same as above, but with function handle <tt>distributedSubmitFcn</tt> | |||
::: ''Cluster nodes' OS'': Select "unix" | |||
::: ''Function called when destroying a job'': Enter <tt>destroyJobFcn</tt> | |||
::: ''Function called when getting the job state'': Enter <tt>getJobStateFcn</tt> | |||
::: ''Job data location is accessible from both client and cluster nodes'': Select "False" | |||
::In the register card "Tasks", option ''Return command window output'': Select "True"<br><br>[[Image:GenericSchedulerConfig_Tasks.jpg|671px|600px]]<br><br> | |||
After these preparations, you can validate your setup by pressing the ''Start Validation'' button in the Configurations manager. When the jobs are transferred to the cluster, you will be prompted for your username and password. | |||
'''Note:''' Regarding the validation procedure, the most important thing is that the first test stage (namely "Find Resources") succeeds. It is common that by using the configuration detailed above, the Distributed Job, Parallel Job or Matlabpool test stages fail (due to the fact that the time needed to allocate and properly start up, say, 36 worker, exceed some test intrinsic timeouts). However, if you temporarily reduce the "Number of workers available to the scheduler" to, say, 4, all test stages will be completed successfully. | |||
== Basic MDCS usage: Example of a task-parallel job == | |||
== | The following example illustrates how to submit a job to the cluster (FLOW or HERO). After you have entered the <tt>batch</tt> command and the command returned with no error, you could, e.g., do some other MATLAB computations, close your MATLAB session, or even power down your machine. In the meantime, your MDCS job gets executed "in the background". After it has finished, you can analyse the results, visualize them, etc. | ||
As an elementary example of an "embarrassingly parallel" (or "task-parallel" in MATLAB terminology) problem we take a parameter sweep of a 2<sup>nd</sup> order ODE (the damped Harmonic Oscillator). The parameters varied are the spring constant (or equivalently, the eigenfrequency) and the damping. For each pair of parameter values and fixed initial condition, the solution of the ODE (up to a certain maximum time) is calculated and the peak value of the amplitude is calculated and stored in an array. | |||
The parameter sweep is achieved in a <tt>for</tt> loop. This can easily be parallelized using <tt>parfor</tt> instead. The total execution time of the <tt>parfor</tt> loop is measured with the <tt>tic</tt> and <tt>toc</tt> commands. | |||
Please download the files containing the [http://www.hpc.uni-oldenburg.de/MDCS/examples/ode/odesystem.m definition of the ODE system] and the [http://www.hpc.uni-oldenburg.de/MDCS/examples/ode/paramSweep_batch.m MATLAB script for the parameter sweep]. | |||
One way to run this code in parallel is to open a Matlabpool of the cluster and then executing the script that performs the parameter sweep. MATLAB then automatically distributes the independent loop iterations across the available workers (or "labs" in this case). Define a "scheduler object" <tt>sched</tt> which describes your cluster configuration (in the above example setup, the configuration named <tt>HERO</tt>), and submit the job to the cluster using the <tt>batch</tt> command: | |||
sched = findResource('scheduler', 'Configuration', 'HERO'); | |||
job = batch(sched, 'paramSweep_batch', 'matlabpool', 7, 'FileDependencies', {'odesystem.m'}); | |||
The first time you submit a job to the cluster in a MATLAB session, you will be prompted for your credentials (username, password). Please enter your usual cluster account data. | |||
The number of "labs" is 1 + the number specified after the <tt>'matlabpool'</tt> keyword. Thus in the above example, the job would run on eight workers. The specification of the file dependencies is necessary since the script <tt>paramSweep_batch.m</tt> depends on <tt>odesystem.m</tt> and thus the latter must be copied to the cluster such that the script can run there (that is one of the purposes of the local and remote "job data" directories that must be specified in the configuration of the scheduler, see above). | |||
Check the state of the job with the Job Monitor (from the Main menue: ''Parallel'' -> ''Job Monitor''), or in the command window: | |||
job.State | |||
By typing | |||
job | |||
you get additional useful information like, e.g., the start time of the job (if it has already started running), the current runtime, etc. | |||
In order to analyze results after the job has finished, load the job data into the workspace: | |||
jobData=load(job); | |||
Check the runtime of the job: | |||
jobData.t1 | |||
You can visualize the results by: | |||
figure; | |||
f=surf(jobData.bVals, jobData.kVals, jobData.peakVals); | |||
set(f,'LineStyle','none'); | |||
set(f,'FaceAlpha',0.5); | |||
xlabel('Damping'); ylabel('Stiffness'); zlabel('Peak Displacement'); | |||
view(50, 30); | |||
If you no longer need the job, clean up (includes deletion of all files related to the job in the local job data directory): | |||
delete(job); | |||
The following table shows the runtime measured on the HERO cluster as a function of the number of workers: | |||
{| class="wikitable" | |||
|- | |||
! Number of workers !! Runtime | |||
|- | |||
| 1 (serial job) || 220s | |||
|- | |||
| 2 || 196s | |||
|- | |||
| 4 || 69s | |||
|- | |||
| 8 || 35s | |||
|- | |||
| 16 || 17s | |||
|- | |||
| 32 || 8.5s | |||
|} | |||
Obviously, the simple parallelization strategy using the <tt>parfor</tt> loop leads to a significant speed-up in this case. | |||
== Advanced usage: Specifying resources == | |||
Any job running on the cluster must specify certain resources (e.g., runtime, memory, disk space) which are passed to SGE as options to the <tt>qsub</tt> command. If you submit jobs to the cluster via MDCS, you do not directly access SGE and, usually, do not have to care at all about these resource requests. MATLAB has been configured to choose reasonable default values (e.g., a runtime of 24 hours, 1.5 GB memory per worker, 50 GB disk space) and to correctly pass them to SGE. The default values for runtime, memory, and disk space are printed when you submit a MATLAB job via MDCS. | |||
However, it is possible to modify these resource requirements for an MDCS jobs from within the MATLAB session if necessary (e.g., if your job runs longer than 24 hours, needs more memory, etc.). That also makes sense if the requirements are significantly lower than the default values (e.g., the runtime is only one hour, the memory requirements much lower, etc.), since that would avoid unnecessary blocking of resources and also increase the chance that the job starts earlier if the cluster is under heavy load. In principle, everything that one would usually write into an SGE job submission script could also be specified from within a MATLAB session when one submits an MDCS job. | |||
The following resource specifications have been implemented: | |||
runtime | |||
memory | |||
diskspace | |||
These correspond, in SGE language, to the <tt>h_rt</tt>, <tt>h_vmem</tt>, and <tt>h_fsize</tt> resource attributes, respectively. The <tt>runtime</tt> must be specified in the format <tt>''hh:mm:ss''</tt> (hours, minutes, seconds), and must not be longer than 8 days. The other resources as a positive (integer) number followed by <tt>K</tt> (for ''Kilobyte''), <tt>M</tt> (for ''Megabyte''), or <tt>G</tt> (for ''Gigabyte''). If you want to change any of these resources from its defaults, you have to add optional arguments to one of the functions | |||
<tt>distributedSubmitFcn</tt> or <tt>parallelSubmitFcn</tt>, depending on whether it is a distributed or parallel job (e.g., if you open a Matlabpool, it is by definition always a "parallel" job). | |||
==== Example (modifying runtime and memory) ==== | |||
Your parallel (Matlabpool) job has a runtime of at most 3 days (with a suitable safety margin) and needs 4 GB of memory per worker. If you are a HERO user, you would then first define a "scheduler" object, and then modify the <tt>ParallelSubmitFcn</tt> (supply additional parameters) of that object: | |||
sched = findResource('scheduler', 'Configuration', 'HERO'); | |||
set(sched, 'ParallelSubmitFcn', cat(1,sched.ParallelSubmitFcn,'runtime','72:0:0','memory','4G')); | |||
The job can be submitted, e.g., via the <tt>batch</tt> command, but you also have to specify the scheduler object as first argument since otherwise the default configuration would be chosen: | |||
job = batch(sched, 'paramSweep_batch', 'matlabpool', 7, 'FileDependencies', {'odesystem.m'}); | |||
You will see the modified values of the resources from the messages printed when you submit the job. | |||
== Material from the Workshop on Parallel Computing with MATLAB (February 19, 2013) == | |||
==== Slides ==== | ==== Slides ==== | ||
| Line 32: | Line 154: | ||
==== Links ==== | ==== Links ==== | ||
* [http://www.mathworks.de/products/parallel-computing/ Parallel | * [http://www.mathworks.de/products/parallel-computing/ Parallel Computing Toolbox] | ||
* [http://www.mathworks.de/products/distriben/ Distributed Computing Server] | * [http://www.mathworks.de/products/distriben/ MATLAB Distributed Computing Server] | ||
* [http://www.mathworks.de/products/distriben/webinars.html Distributed Computing Server Webinars] | * [http://www.mathworks.de/products/distriben/webinars.html MATLAB Distributed Computing Server Webinars] | ||
* [http://www.mathworks.de/academia/ Material for Academia] | * [http://www.mathworks.de/academia/ Material for Academia] | ||
== Documentation == | == Documentation == | ||
* <span class="pops">[[Media: | * <span class="pops">[[Media:MATLAB_GettingStarted_R2011b.pdf|MATLAB Getting Started Guide (R2011b)]]</span> | ||
* <span class="pops">[[Media: | * <span class="pops">[[Media:MATLAB_ParCompTb_UsersGuide_R2011b.pdf|Parallel Computing Toolbox User's Guide (R2011b)]]</span> | ||
Latest revision as of 13:27, 10 April 2015
NOTE: This page explains the configuration and use of Matlab R2011b and earlier. For R2014b, refer to Configuration MDCS and MDCS Basic Example. If you are starting to use Matlab it is recommended to use the latest version available on the cluster.
Benefits of MDCS
With MDCS, you can submit both serial as well as parallel jobs to one of the central HPC clusters from within your local MATLAB session. There is no need to deal with SGE, or even to log-on to the HPC systems. The internal structure of the clusters is hidden to the end user, they merely act like "black boxes" connected to your local machine and providing you with powerful computational resources. On the other hand, jobs submitted via MDCS are fully integrated into SGE, and have the same rights and privileges like any other SGE batch job. Thus there is no conflict between MATLAB jobs submitted via MDCS and standard SGE batch jobs.
Using MDCS for MATLAB computations on the central HPC facilities has a number of advantages, e.g.:
- Simplified workflow for those who exclusively do their numerics with MATLAB: they can do development, production of results, and post-processing within a unified environment (the MATLAB desktop).
- A "worker" (= MATLAB session without a user interface) does not check out any "regular" MATLAB license or, what is even more, any Toolbox license even if functions or utilities of the Toolbox are used by the worker; all Toolboxes to which the client which the job was submitted from has access to (regardless whether they are actually checked out by the client or not) can be used by the workers.Considering that the University has only 200 MATLAB licenses, but there are 224 MDCS worker licenses, it immediately becomes clear that the total number of MATLAB licenses for all users in the University is effectively more than doubled! The effect is even more pronounced for the Toolboxes: e.g., there are only 50 licenses for the Statistics Toolbox, but with MDCS an additional "effective" 224 licenses for this Toolbox become available (analogous for all other toolboxes).
To allow for a fair sharing of resources, the number of worker licenses a single user can check out at a given instance has been limited to 36. This should be compared to the situation before the introduction of MDCS: how often could one user get access to 36, say, Statistics Toolbox or Signal Processing Toolbox licenses at a time? At peak times, all such licenses are usually checked out.) - The Parallel Computing Toolbox on your local machine only allows you to use a maximum of 12 workers simultaneously. With MDCS, you can define parallel jobs using more than 12 workers and running across different hosts (compute nodes). Moreover, the Parallel Computing Toolbox provides utilities which simplify the parallelization of MATLAB code. E.g., for "embarrassingly parallel" (aka task-parallel) problems, which are quite common in practice (parameter sweeps, data analyses where the same operations are performed on a set of data, etc.), the parfor loop and other tools allow for an easy and rather efficient parallelization. Similarly, for communicating (aka data-parallel) jobs, which are the MATLAB analogue of MPI jobs (implementing the "single program, multiple data" paradigm), tools for "automated" parallelization are available, too, in particular for Linear Algebra operations (distributed and co-distributed arrays). In conjunction with MDCS and the possibility to use the powerful cluster resources, this can lead to a significant speed-up of your MATLAB computations.
Therefore, all MATLAB computations on the clusters should by default be done via MDCS. Of course, it is still possible to submit MATLAB Jobs as regular SGE jobs (by writing the command that starts MATLAB in non-interactive mode into the submission script and supplying the necessary input arguments and files), but this strategy is deprecated. It leads, due to the limited number of available MATLAB and Toolbox licenses, to a strong competition between HPC users and other MATLAB users across the University. Moreover, cluster jobs often fail immediately after they have started to run since there are no free licenses available (a reliable, full license integration with SGE is non-trivial to implement). With MDCS, this "license availability problem" does not exist since SGE keeps track of the total number of workers currently used, and if the required resources are not available, the job just stays in the queue like any other batch job.
To use any of the functionalities of MDCS, you need to have the Parallel Computing Toolbox (PCT) installed on your local system.
Prerequisites
Before you can use MDCS and submit jobs to the cluster from within a local MATLAB session, a few preparations are necessary, both on the system-wide (host) levek and on a per-user basis:
- On your local machine (PC, workstation, notebook, ...), you must have one of the following MATLAB releases installed:
- R2010b
- R2011a
- R2011b
If you want to use Matlab R2014b or later, please refer to these instructions for the configuration of MDCS. It is important that your local installation includes all toolboxes, in particular the Parallel Computing Toolbox (PCT). It is recommended to install MATLAB from the media provided by the IT Services on their website and follow the instructions there. In that case, all required components (including the PCT) are automatically installed. - Your local machine must be able to connect to the login nodes of the clusters (flow.hpc.uni-oldenburg.de or hero.hpc.uni-oldenburg.de) via ssh.
- The system administrator responsible for your local machine must install a couple of files into the directory
matlabroot/toolbox/local
on a Unix/Linux system, or the analogous location for Windows clients. These are the SGE integration files provided by MDCS, which have been customized for our clusters. The names of the files are:
createSubmitScript.m
destroyJobFcn.m
distributedJobWrapper.sh
distributedSubmitFcn.m
extractJobId.m
getJobStateFcn.m
getRemoteConnection.m
getSubmitString.m
parallelJobWrapper.sh
parallelSubmitFcn.m
startup.m
The required SGE integration files can be downloaded as a single zipped archive. After downloading, you (or your system adminstrator) can unpack the archive and copy the files to the directory mentioned above. - The only file from the previous step that needs modification is startup.m. There, the fully-qualified hostname of your local machine must be substituted. Thus, the only line in the file
pctconfig('hostname','myhost.uni-oldenburg.de');
could be changed, e.g., into
pctconfig('hostname','celeborn.physik.uni-oldenburg.de');
Note, that you adminstrator rights for this step, too (Windows: open editor as admin, Linux: use sudo). - The following steps must be completed by each user. Start a new MATLAB session and bring up the Parallel Configurations Manager by selecting Parallel -> Manage Configurations. Create a new "Generic Scheduler" Configuration (File -> New -> Generic):
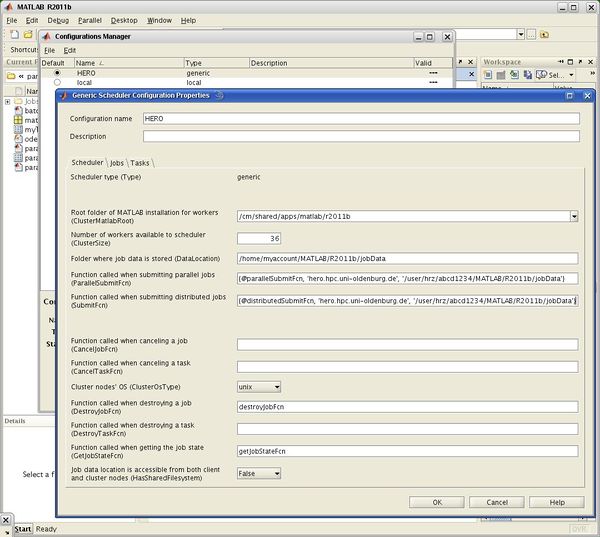
The following fields and boxes must be modified in the register card "Scheduler"

- Configuration Name: MATLAB name of the configuration (e.g., HERO or FLOW, but could be any name)
- Root folder of MATLAB installation for workers: E.g., /cm/shared/apps/matlab/r2011b if you have R2011b installed on your local machine (otherwise, replace "r2011b" by the appropriate release string; please note the lower cases)
- Number of workers available to scheduler: Set this to 36 (the maximum number of workers per user)
- Folder where job data is stored: A directory on your local machine, typically inside your homedirectory, where you have read and write access as, e.g., /home/myaccount/MATLAB/R2011b/jobData (note that this directory must already exist, it will not be created automatically!)
- Function called when submitting parallel jobs: Here you must specify a cell array containing a function handle, the submit host on the cluster, and the location on the remote system where job data are stored (analogous to the "local" job data directory). If you are a user of HERO, the entry could look as follows:
{@parallelSubmitFcn,'hero.hpc.uni-oldenburg.de','/user/hrz/abcd1234/MATLAB/R2011b/jobData'} (note that this directory must already exist, it will not be created automatically!)
- Function called when submitting parallel jobs: Here you must specify a cell array containing a function handle, the submit host on the cluster, and the location on the remote system where job data are stored (analogous to the "local" job data directory). If you are a user of HERO, the entry could look as follows:
- Function called when submitting distributed jobs: Same as above, but with function handle distributedSubmitFcn
- Cluster nodes' OS: Select "unix"
- Function called when destroying a job: Enter destroyJobFcn
- Function called when getting the job state: Enter getJobStateFcn
- Job data location is accessible from both client and cluster nodes: Select "False"
- In the register card "Tasks", option Return command window output: Select "True"
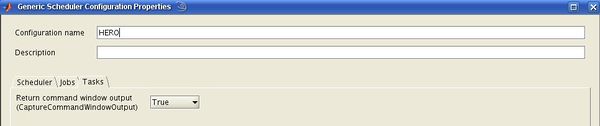
- In the register card "Tasks", option Return command window output: Select "True"

After these preparations, you can validate your setup by pressing the Start Validation button in the Configurations manager. When the jobs are transferred to the cluster, you will be prompted for your username and password.
Note: Regarding the validation procedure, the most important thing is that the first test stage (namely "Find Resources") succeeds. It is common that by using the configuration detailed above, the Distributed Job, Parallel Job or Matlabpool test stages fail (due to the fact that the time needed to allocate and properly start up, say, 36 worker, exceed some test intrinsic timeouts). However, if you temporarily reduce the "Number of workers available to the scheduler" to, say, 4, all test stages will be completed successfully.
Basic MDCS usage: Example of a task-parallel job
The following example illustrates how to submit a job to the cluster (FLOW or HERO). After you have entered the batch command and the command returned with no error, you could, e.g., do some other MATLAB computations, close your MATLAB session, or even power down your machine. In the meantime, your MDCS job gets executed "in the background". After it has finished, you can analyse the results, visualize them, etc.
As an elementary example of an "embarrassingly parallel" (or "task-parallel" in MATLAB terminology) problem we take a parameter sweep of a 2nd order ODE (the damped Harmonic Oscillator). The parameters varied are the spring constant (or equivalently, the eigenfrequency) and the damping. For each pair of parameter values and fixed initial condition, the solution of the ODE (up to a certain maximum time) is calculated and the peak value of the amplitude is calculated and stored in an array.
The parameter sweep is achieved in a for loop. This can easily be parallelized using parfor instead. The total execution time of the parfor loop is measured with the tic and toc commands.
Please download the files containing the definition of the ODE system and the MATLAB script for the parameter sweep.
One way to run this code in parallel is to open a Matlabpool of the cluster and then executing the script that performs the parameter sweep. MATLAB then automatically distributes the independent loop iterations across the available workers (or "labs" in this case). Define a "scheduler object" sched which describes your cluster configuration (in the above example setup, the configuration named HERO), and submit the job to the cluster using the batch command:
sched = findResource('scheduler', 'Configuration', 'HERO');
job = batch(sched, 'paramSweep_batch', 'matlabpool', 7, 'FileDependencies', {'odesystem.m'});
The first time you submit a job to the cluster in a MATLAB session, you will be prompted for your credentials (username, password). Please enter your usual cluster account data. The number of "labs" is 1 + the number specified after the 'matlabpool' keyword. Thus in the above example, the job would run on eight workers. The specification of the file dependencies is necessary since the script paramSweep_batch.m depends on odesystem.m and thus the latter must be copied to the cluster such that the script can run there (that is one of the purposes of the local and remote "job data" directories that must be specified in the configuration of the scheduler, see above).
Check the state of the job with the Job Monitor (from the Main menue: Parallel -> Job Monitor), or in the command window:
job.State
By typing
job
you get additional useful information like, e.g., the start time of the job (if it has already started running), the current runtime, etc.
In order to analyze results after the job has finished, load the job data into the workspace:
jobData=load(job);
Check the runtime of the job:
jobData.t1
You can visualize the results by:
figure;
f=surf(jobData.bVals, jobData.kVals, jobData.peakVals);
set(f,'LineStyle','none');
set(f,'FaceAlpha',0.5);
xlabel('Damping'); ylabel('Stiffness'); zlabel('Peak Displacement');
view(50, 30);
If you no longer need the job, clean up (includes deletion of all files related to the job in the local job data directory):
delete(job);
The following table shows the runtime measured on the HERO cluster as a function of the number of workers:
| Number of workers | Runtime |
|---|---|
| 1 (serial job) | 220s |
| 2 | 196s |
| 4 | 69s |
| 8 | 35s |
| 16 | 17s |
| 32 | 8.5s |
Obviously, the simple parallelization strategy using the parfor loop leads to a significant speed-up in this case.
Advanced usage: Specifying resources
Any job running on the cluster must specify certain resources (e.g., runtime, memory, disk space) which are passed to SGE as options to the qsub command. If you submit jobs to the cluster via MDCS, you do not directly access SGE and, usually, do not have to care at all about these resource requests. MATLAB has been configured to choose reasonable default values (e.g., a runtime of 24 hours, 1.5 GB memory per worker, 50 GB disk space) and to correctly pass them to SGE. The default values for runtime, memory, and disk space are printed when you submit a MATLAB job via MDCS.
However, it is possible to modify these resource requirements for an MDCS jobs from within the MATLAB session if necessary (e.g., if your job runs longer than 24 hours, needs more memory, etc.). That also makes sense if the requirements are significantly lower than the default values (e.g., the runtime is only one hour, the memory requirements much lower, etc.), since that would avoid unnecessary blocking of resources and also increase the chance that the job starts earlier if the cluster is under heavy load. In principle, everything that one would usually write into an SGE job submission script could also be specified from within a MATLAB session when one submits an MDCS job.
The following resource specifications have been implemented:
runtime memory diskspace
These correspond, in SGE language, to the h_rt, h_vmem, and h_fsize resource attributes, respectively. The runtime must be specified in the format hh:mm:ss (hours, minutes, seconds), and must not be longer than 8 days. The other resources as a positive (integer) number followed by K (for Kilobyte), M (for Megabyte), or G (for Gigabyte). If you want to change any of these resources from its defaults, you have to add optional arguments to one of the functions distributedSubmitFcn or parallelSubmitFcn, depending on whether it is a distributed or parallel job (e.g., if you open a Matlabpool, it is by definition always a "parallel" job).
Example (modifying runtime and memory)
Your parallel (Matlabpool) job has a runtime of at most 3 days (with a suitable safety margin) and needs 4 GB of memory per worker. If you are a HERO user, you would then first define a "scheduler" object, and then modify the ParallelSubmitFcn (supply additional parameters) of that object:
sched = findResource('scheduler', 'Configuration', 'HERO');
set(sched, 'ParallelSubmitFcn', cat(1,sched.ParallelSubmitFcn,'runtime','72:0:0','memory','4G'));
The job can be submitted, e.g., via the batch command, but you also have to specify the scheduler object as first argument since otherwise the default configuration would be chosen:
job = batch(sched, 'paramSweep_batch', 'matlabpool', 7, 'FileDependencies', {'odesystem.m'});
You will see the modified values of the resources from the messages printed when you submit the job.
Material from the Workshop on Parallel Computing with MATLAB (February 19, 2013)
Slides
Links
- Parallel Computing Toolbox
- MATLAB Distributed Computing Server
- MATLAB Distributed Computing Server Webinars
- Material for Academia